import urllib.request
import urllib.parse
import re
#保存HTML源码
def saveFile(data):
path = "D:\\python\\Spider\\58\\html.out"
f = open(path,'wb')
f.write(data)
f.close()
#所需要的数据,考虑到正则匹配的水平太差,就挑了好拿的部分
content = {}
content['tingshi'] = []
content['daxiao'] = []
content['chaoxiang'] = []
content['louceng'] = []
content['jiedao'] = []
content['price'] = []
name = ['tingshi','daxiao','chaoxiang','louceng','jiedao']
#正则匹配式
res_tr1 = r"<ul class='house-list-wrap'>(.*?)</ul>"
res_tr2 = r"<span>(.*?)</span>"
res_price = r'<b>(.*?)</b>'
res_jiedao = r'<a>(.*?)</a>'
def getdata(datalist):
num = -1
for x in datalist:
num = num + 1
num = num%6;
if num == 5:
continue
if num < 4:
print(x)
content[name[num]].append(x)
if num == 4:
content[name[num]].append(re.findall(res_jiedao,x,re.S|re.M))
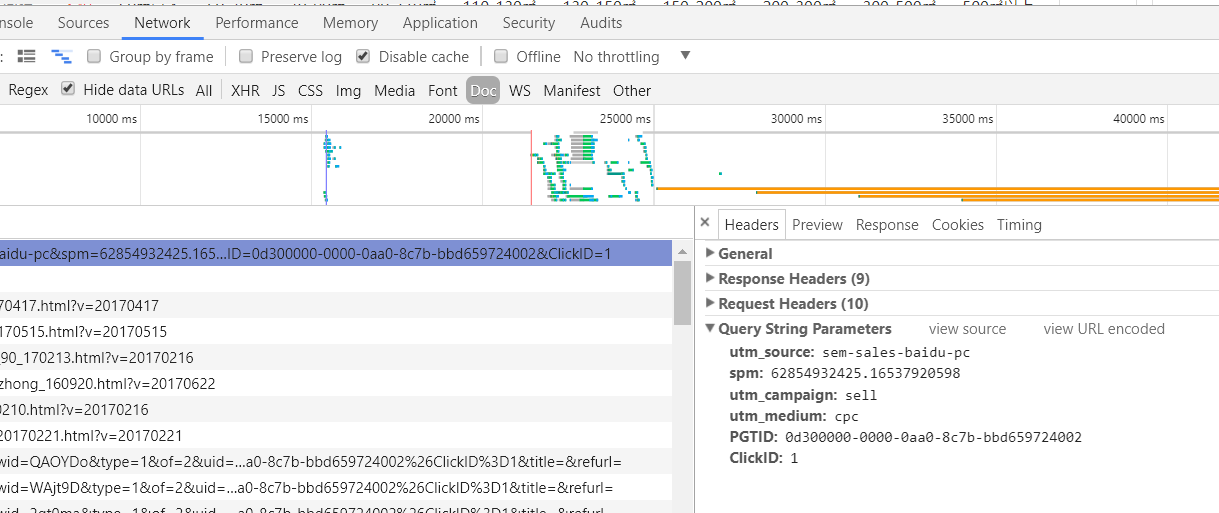
url='http://hz.58.com/jianggan/ershoufang/pn3/?'
data={}
head={}
head['User-Agent']='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36'
data['utm_source']='sem-sales-baidu-pc'
data['utm_campaign']='sell'
data['utm_medium']='cpc'
data['spm']='62854932425.16537920598'
data['PGTID']='0d300000-0000-0a0c-8067-a60b6ee48510'
data['ClickID']=1
data=urllib.parse.urlencode(data).encode('utf-8')
req=urllib.request.Request(url,data,head,method='GET')
req = urllib.request.urlopen(req)
my_data = req.read()
saveFile(my_data)
#匹配出ul标签内数据
my_strdata = bytes.decode(my_data)
m_list1 = re.findall(res_tr1,my_strdata,re.S|re.M)
m_tr1 = "".join(m_list1)
content['price'] = re.findall(res_price,m_tr1,re.S|re.M)
m_list2 = re.findall(res_tr2,m_tr1,re.S|re.M)
getdata(m_list2)
print(content)